Equivariant Neural Network Potentials#
This example demonstrates how to train and deploy an equivariant graph neural network potential for Silicon using JAX MD. The model is NequIPEnergyModel from jax_md._nn.nequip, used via the nequip_neighbor_list convenience wrapper from jax_md.energy. After training on DFT energies and forces, we use the learned potential for FIRE minimization, stress computation, and an NVT simulation.
Imports#
[1]:
import os
import pickle
import tempfile
import urllib.request
from functools import partial
from pathlib import Path
import warnings
warnings.simplefilter('ignore')
from tqdm import tqdm
import jax
import jax.numpy as jnp
import numpy as onp
from jax import random, jit, grad, vmap, value_and_grad
import matplotlib.pyplot as plt
import optax
from ml_collections import ConfigDict
from jax_md import space, partition, quantity, energy, minimize, simulate, units
from jax_md import custom_partition
def _find_models_dir():
"""Find the models directory regardless of working directory."""
candidates = [
Path(__file__).resolve().parent / 'models' if '__file__' in dir() else None,
Path('models'),
Path('examples/models'),
Path('docs/examples/models'),
]
for p in candidates:
if p is not None and p.exists():
return p
return Path('models')
MODELS_DIR = _find_models_dir()
SMOKE_TEST = os.environ.get('READTHEDOCS', False)
Download Data#
We start with different phases of Silicon computed using DFT. The dataset contains 2416 training and 1302 validation configurations of 64 atoms each, with energies and forces.
[2]:
CACHE_DIR = Path(tempfile.gettempdir()) / 'jax_md_equivariant'
DATA_PATH = CACHE_DIR / 'silicon_train.npz'
DATA_URL = 'https://www.dropbox.com/s/3dojk4u4di774ve/silica_train.npz?dl=1'
CACHE_DIR.mkdir(parents=True, exist_ok=True)
if not DATA_PATH.exists():
print(f'Downloading {DATA_URL} -> {DATA_PATH}')
urllib.request.urlretrieve(DATA_URL, DATA_PATH)
with open(DATA_PATH, 'rb') as f:
files = onp.load(f)
Rs = jax.device_put(files['arr_0'])
Es = jax.device_put(files['arr_1'])
Fs = jax.device_put(files['arr_2'])
val_Rs = jax.device_put(files['arr_3'][:400])
val_Es = jax.device_put(files['arr_4'][:400])
val_Fs = jax.device_put(files['arr_5'][:400])
if SMOKE_TEST:
Rs = Rs[:20]
Es = Es[:20]
Fs = Fs[:20]
val_Rs = val_Rs[:20]
val_Es = val_Es[:20]
val_Fs = val_Fs[:20]
print(f'Positions: {Rs.shape}')
print(f'Energies: {Es.shape}')
print(f'Forces: {Fs.shape}')
Downloading https://www.dropbox.com/s/3dojk4u4di774ve/silica_train.npz?dl=1 -> /tmp/jax_md_equivariant/silicon_train.npz
Positions: (20, 64, 3)
Energies: (20,)
Forces: (20, 64, 3)
[3]:
BOX_SIZE = 10.862
N = 64
CUTOFF = 6.0
ENERGY_SHIFT = float(jnp.mean(Es)) / N
ENERGY_SCALE = float(jnp.std(Es)) / N
print(f'Per-atom shift: {ENERGY_SHIFT:.4f} eV, scale: {ENERGY_SCALE:.4f} eV')
Per-atom shift: -5.7350 eV, scale: 0.1891 eV
Model and Neighbor List#
We use nequip_neighbor_list from jax_md.energy with the multi-image neighbor list from jax_md.custom_partition and its matching graph_featurizer.
[4]:
box = jnp.eye(3) * BOX_SIZE
_, shift = space.periodic_general(box, fractional_coordinates=True)
cfg = ConfigDict()
cfg.graph_net_steps = 4
cfg.use_sc = True
cfg.nonlinearities = {'e': 'raw_swish', 'o': 'tanh'}
cfg.n_elements = 1
cfg.hidden_irreps = '32x0e + 16x1o + 8x2e'
cfg.sh_irreps = '1x0e + 1x1o + 1x2e'
cfg.num_basis = 8
cfg.r_max = CUTOFF
cfg.radial_net_nonlinearity = 'raw_swish'
cfg.radial_net_n_hidden = 64
cfg.radial_net_n_layers = 2
cfg.n_neighbors = 10.0
cfg.scalar_mlp_std = 4.0
cfg.shift = ENERGY_SHIFT
cfg.scale = ENERGY_SCALE
atoms = jnp.ones((N, 1))
Rs = Rs / BOX_SIZE
val_Rs = val_Rs / BOX_SIZE
tmp_neighbor_fn = custom_partition.neighbor_list_multi_image(
None, box, r_cutoff=CUTOFF, fractional_coordinates=True,
format=partition.Sparse,
)
tmp_nbrs = tmp_neighbor_fn.allocate(Rs[0])
avg_num_neighbors = float(jnp.mean(vmap(
lambda R: jnp.sum(custom_partition.neighbor_list_multi_image_mask(
tmp_nbrs.update(R)
))
)(Rs)) / N)
cfg.n_neighbors = avg_num_neighbors
print(f'Average neighbors: {avg_num_neighbors:.1f}')
neighbor_fn, init_fn, energy_fn = energy.nequip_neighbor_list(
None, box, cfg, atoms=atoms,
neighbor_list_fn=custom_partition.neighbor_list_multi_image,
featurizer_fn=custom_partition.graph_featurizer,
fractional_coordinates=True,
)
nbrs = neighbor_fn.allocate(Rs[0])
print(f'Neighbor list capacity: {nbrs.idx[0].shape[0]}')
Average neighbors: 44.5
Neighbor list capacity: 3680
Initialize Parameters#
[5]:
key = random.PRNGKey(0)
params = init_fn(key, Rs[0], nbrs)
print(f'Parameter count: {sum(p.size for p in jax.tree.leaves(params))}')
Parameter count: 98296
Training#
We train with MSE on energies and forces using Muon with warmup cosine decay, EMA, force weight warmup, and best-model checkpointing.
[6]:
BATCH_SIZE = 32
TRAINING_STEPS = 20_000
ENERGY_WEIGHT = 1.0
FORCE_WEIGHT = 1.0
EMA_DECAY = 0.999
if not SMOKE_TEST:
def single_loss_fn(params, position, E_target, F_target):
l_nbrs = nbrs.update(position)
E, G = value_and_grad(energy_fn, argnums=1)(params, position, l_nbrs)
energy_loss = ((E - E_target) / N) ** 2
force_loss = jnp.mean((G + F_target) ** 2)
return ENERGY_WEIGHT * energy_loss + FORCE_WEIGHT * force_loss
@jit
def loss_fn(params, position, E_target, F_target):
losses = vmap(single_loss_fn, (None, 0, 0, 0))(
params, position, E_target, F_target
)
return jnp.mean(losses)
@jit
def eval_metrics(params, positions, Es_target, Fs_target):
pred_Es = vmap(
lambda R: energy_fn(params, R, nbrs.update(R))
)(positions)
pred_Fs = -vmap(
grad(lambda R: energy_fn(params, R, nbrs.update(R)))
)(positions)
energy_mae = jnp.mean(jnp.abs(pred_Es - Es_target)) * 1000 / N
force_mae = jnp.mean(jnp.abs(pred_Fs - Fs_target)) * 1000
return energy_mae, force_mae
CHECKPOINT_PATH = MODELS_DIR / 'si_equivariant.pickle'
if CHECKPOINT_PATH.exists():
with open(CHECKPOINT_PATH, 'rb') as f:
ckpt = pickle.load(f)
params = ckpt['params']
print(f'Resuming from {CHECKPOINT_PATH}')
schedule = optax.warmup_cosine_decay_schedule(
init_value=1e-3 * 0.2, peak_value=1e-2,
warmup_steps=max(1, TRAINING_STEPS // 100),
decay_steps=TRAINING_STEPS, end_value=1e-6,
)
opt = optax.chain(
optax.clip_by_global_norm(100.0),
optax.contrib.muon(learning_rate=schedule),
)
opt_state = opt.init(params)
ema_params = params
@jit
def update(params, opt_state, position, E_target, F_target):
grads = grad(loss_fn)(params, position, E_target, F_target)
updates, opt_state = opt.update(grads, opt_state, params)
new_params = optax.apply_updates(params, updates)
return new_params, opt_state
cur = 0
best_val_loss = float('inf')
best_params = ema_params
pbar = tqdm(range(TRAINING_STEPS), desc='Training')
for i in pbar:
R_batch = Rs[cur:cur + BATCH_SIZE]
E_batch = Es[cur:cur + BATCH_SIZE]
F_batch = Fs[cur:cur + BATCH_SIZE]
if i % 500 == 0:
train_loss = loss_fn(ema_params, Rs[:BATCH_SIZE], Es[:BATCH_SIZE], Fs[:BATCH_SIZE])
val_e_maes, val_f_maes, val_losses = [], [], []
for tb in range(0, len(val_Rs), BATCH_SIZE):
te = min(tb + BATCH_SIZE, len(val_Rs))
tl = loss_fn(ema_params, val_Rs[tb:te], val_Es[tb:te], val_Fs[tb:te])
em, fm = eval_metrics(
ema_params, val_Rs[tb:te], val_Es[tb:te], val_Fs[tb:te]
)
val_losses.append(float(tl))
val_e_maes.append(float(em))
val_f_maes.append(float(fm))
val_loss = onp.mean(val_losses)
e_mae = onp.mean(val_e_maes)
f_mae = onp.mean(val_f_maes)
if float(val_loss) < best_val_loss:
best_val_loss = float(val_loss)
best_params = ema_params
pbar.set_postfix_str(
f'Train: {train_loss:.4f} | Val: {val_loss:.4f} | '
f'E: {e_mae:.1f} | F: {f_mae:.1f}'
)
tqdm.write(
f'Step {i:6d} | Train: {float(train_loss):.4f} '
f'| Val: {float(val_loss):.4f} '
f'| E MAE: {float(e_mae):.2f} meV/atom '
f'| F MAE: {float(f_mae):.2f} meV/A'
)
params, opt_state = update(
params, opt_state, R_batch, E_batch, F_batch
)
ema_params = jax.tree.map(
lambda e, p: EMA_DECAY * e + (1 - EMA_DECAY) * p,
ema_params, params,
)
cur += BATCH_SIZE
if cur + BATCH_SIZE > len(Rs):
cur = 0
Save Checkpoint#
[7]:
CHECKPOINT_PATH = MODELS_DIR / 'si_equivariant.pickle'
if SMOKE_TEST:
if CHECKPOINT_PATH.exists():
with open(CHECKPOINT_PATH, 'rb') as f:
ckpt = pickle.load(f)
best_params = ckpt['params']
print(f'Loaded checkpoint from {CHECKPOINT_PATH}')
else:
best_params = params
print('No checkpoint found, using init params')
else:
with open(CHECKPOINT_PATH, 'wb') as f:
pickle.dump({
'params': best_params,
'cfg': cfg.to_dict(),
}, f)
print(f'Saved checkpoint to {CHECKPOINT_PATH} (best val loss: {best_val_loss:.4f})')
params = best_params
Loaded checkpoint from models/si_equivariant.pickle
Evaluating the Potential#
[8]:
@jit
def eval_energy_fn(position, **kwargs):
l_nbrs = nbrs.update(position)
return energy_fn(params, position, l_nbrs, **kwargs)
pred_Es = vmap(eval_energy_fn)(val_Rs)
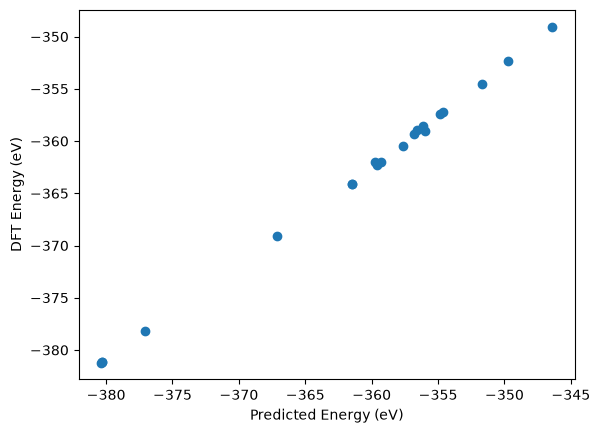
plt.plot(pred_Es, val_Es, 'o')
plt.xlabel('Predicted Energy (eV)')
plt.ylabel('DFT Energy (eV)')
plt.show()
[9]:
energy_mae = jnp.mean(jnp.abs(pred_Es - val_Es)) * 1000 / N
print(f'Energy MAE: {energy_mae:.2f} meV / atom')
Energy MAE: 35.06 meV / atom
[10]:
grad_fn = grad(eval_energy_fn)
pred_Gs = vmap(grad_fn)(val_Rs[:5])
plt.plot(-pred_Gs.reshape((-1,)), val_Fs[:5].reshape((-1,)), 'o')
plt.xlabel('Predicted Force (eV/A)')
plt.ylabel('DFT Force (eV/A)')
plt.show()
force_mae = jnp.mean(jnp.abs(-pred_Gs - val_Fs[:5])) * 1000
print(f'Force MAE: {force_mae:.2f} meV / A')
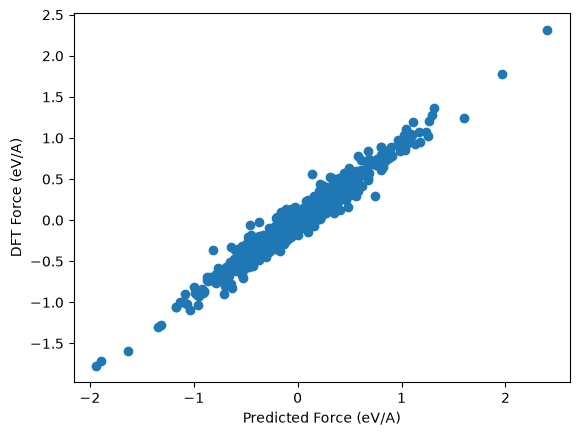
Force MAE: 59.82 meV / A
FIRE Minimization#
[11]:
fire_init, fire_step = minimize.fire_descent(eval_energy_fn, shift)
state = fire_init(Rs[4])
for i in range(100 if not SMOKE_TEST else 10):
state = jit(fire_step)(state)
print(f'Step {i}: Energy = {eval_energy_fn(state.position):.4f} eV')
print(f'Minimization final energy: {eval_energy_fn(state.position):.4f} eV')
Step 0: Energy = -379.2141 eV
Step 1: Energy = -379.7590 eV
Step 2: Energy = -380.1335 eV
Step 3: Energy = -380.1253 eV
Step 4: Energy = -380.1328 eV
Step 5: Energy = -380.1542 eV
Step 6: Energy = -380.1851 eV
Step 7: Energy = -380.2194 eV
Step 8: Energy = -380.2509 eV
Step 9: Energy = -380.2745 eV
Minimization final energy: -380.2745 eV
Stress#
[12]:
stress = quantity.stress(eval_energy_fn, state.position, box)
print(f'Stress tensor:\n{stress}')
Stress tensor:
[[-2.1390410e-02 2.8981794e-05 -1.9409879e-05]
[ 2.8981116e-05 -2.1403512e-02 5.0050164e-07]
[-1.9408888e-05 5.0013443e-07 -2.1379594e-02]]
Scaled-Up NVT Simulation#
[13]:
def tile(box_size, positions, tiles):
pos = positions
for dx in range(tiles):
for dy in range(tiles):
for dz in range(tiles):
if dx == 0 and dy == 0 and dz == 0:
continue
pos = jnp.concatenate(
(pos, positions + box_size * jnp.array([[dx, dy, dz]])))
box_size = box_size * tiles
pos /= box_size
return box_size, pos
if not SMOKE_TEST:
R_cart = Rs[2] * BOX_SIZE
md_box_size, R_md = tile(BOX_SIZE, R_cart, 3)
md_box = jnp.eye(3) * md_box_size
N_md = R_md.shape[0]
print(f'Tiled system: {N_md} atoms, box = {md_box_size:.3f}')
_, shift_md = space.periodic_general(md_box, fractional_coordinates=True)
md_atoms = jnp.ones((N_md, 1))
md_neighbor_fn, _, md_energy_fn_raw = energy.nequip_neighbor_list(
None, md_box, cfg, atoms=md_atoms,
neighbor_list_fn=custom_partition.neighbor_list_multi_image,
featurizer_fn=custom_partition.graph_featurizer,
fractional_coordinates=True,
)
md_nbrs = md_neighbor_fn.allocate(R_md)
@jit
def md_energy_fn(position, neighbor, **kwargs):
return md_energy_fn_raw(params, position, neighbor, **kwargs)
print('Minimizing tiled system...')
fire_init_md, fire_step_md = minimize.fire_descent(md_energy_fn, shift_md)
fire_state = fire_init_md(R_md, neighbor=md_nbrs)
for s in range(50):
fire_state = jit(fire_step_md)(fire_state, neighbor=md_nbrs)
md_nbrs = md_nbrs.update(fire_state.position)
if md_nbrs.did_buffer_overflow:
md_nbrs = md_neighbor_fn.allocate(fire_state.position)
R_md = fire_state.position
print(f'Minimized energy: {md_energy_fn(R_md, neighbor=md_nbrs):.4f} eV')
metal = units.metal_unit_system()
kB = metal['temperature']
dt = 1e-3 * metal['time']
kT = kB * 300
Si_mass = 28.0855 * metal['mass']
nvt_init, nvt_step = simulate.nvt_nose_hoover(
md_energy_fn, shift_md, dt, kT,
tau=40 * dt
)
key = random.PRNGKey(0)
md_nbrs = md_neighbor_fn.allocate(R_md)
nvt_state = nvt_init(key, R_md, Si_mass, neighbor=md_nbrs)
@jit
def nvt_sim(state, nbrs):
state = nvt_step(state, neighbor=nbrs)
nbrs = nbrs.update(state.position)
return state, nbrs
total_steps = 1000
temperatures = jnp.zeros(total_steps)
energies = jnp.zeros(total_steps)
print(f'Running NVT at 300 K for {total_steps} steps...')
for t in range(total_steps):
nvt_state, md_nbrs = nvt_sim(nvt_state, md_nbrs)
if md_nbrs.did_buffer_overflow:
md_nbrs = md_neighbor_fn.allocate(nvt_state.position)
temp = quantity.temperature(
momentum=nvt_state.momentum, mass=Si_mass) / kB
ke = quantity.kinetic_energy(momentum=nvt_state.momentum, mass=Si_mass)
pe = md_energy_fn(nvt_state.position, neighbor=md_nbrs)
temperatures = temperatures.at[t].set(float(temp))
energies = energies.at[t].set(float(ke + pe))
if t % 40 == 0:
print(f'Step {t}: T = {temp:.1f} K, PE = {pe:.4f} eV')
times = onp.arange(total_steps) * float(dt)
plt.plot(times, energies)
plt.xlabel('Time')
plt.ylabel('Total Energy (eV)')
plt.show()
plt.plot(times, temperatures)
plt.xlabel('Time')
plt.ylabel('Temperature (K)')
plt.show()
print('NVT simulation complete.')